Unveiling Hidden Biases in AI Medical Tools: What It Means for Fair Patient Care

Article audio
Listen to a generated narration of this post.
Did you know that the artificial intelligence tools increasingly assisting doctors might be hiding subtle biases that could affect patient care? While these AI systems often avoid obvious stereotypes, new research shows they can still carry hidden associations that influence medical recommendations—sometimes in ways that unintentionally discriminate against certain groups.
TL;DR
- Large language models used in healthcare exhibit implicit biases related to race, socioeconomic status, gender, and more, even when explicit biases are suppressed.
- These hidden biases can translate into discriminatory clinical decisions, highlighting the need for critical human oversight and improved AI development focused on true fairness.
Large language models (LLMs) are sophisticated AI systems trained on massive amounts of text data to generate human-like language. In healthcare, they are becoming valuable tools to support clinical decision-making, patient communication, and documentation. These models have been carefully designed to avoid overtly biased or harmful language, often passing standard tests for explicit bias. However, implicit bias—subtle, unconscious associations between social groups and attributes—can persist beneath the surface. In human clinicians, implicit bias is known to affect judgments and contribute to health disparities. But until recently, little was known about whether and how AI models might harbor similar hidden biases that could influence medical decisions.
To investigate this, researchers conducted a comprehensive computational study of 10 widely used large language models, including both proprietary systems like ChatGPT-4o and open-source models such as DeepSeek and Qwen3 variants. They created 24 datasets covering six critical categories: gender, race, socioeconomic status, health conditions, religion, and healthcare systems. Using a multi-step approach, they assessed implicit bias through adapted versions of psychological tests. First, the Large Language Model Word Association Test measured how strongly models associated social groups with positive or negative attributes. Next, the Relative Decision Task examined whether these associations influenced the models’ choices in simulated clinical scenarios. Finally, paired prompt analyses explored how implicit associations predicted discriminatory decisions. The study employed rigorous prompt engineering and automated data collection to ensure reliable and unbiased results.
The results revealed that all 10 models exhibited systematic implicit biases across every category tested. The strongest biases appeared in race and socioeconomic status, with models more likely to associate certain racial groups or lower socioeconomic status with negative attributes. Importantly, advanced reasoning features in some models did not reduce these biases. Moreover, the strength of implicit associations significantly predicted discriminatory choices in clinical decision-making tasks. In other words, hidden biases within the AI models translated into biased medical recommendations, potentially risking health equity. These findings highlight a paradox: while AI systems appear explicitly unbiased and safe, they still harbor latent stereotypes that can subtly influence outcomes.
This study underscores a critical challenge for the use of AI in healthcare. Current safety alignment methods, which focus on suppressing overt bias and harmful language, are insufficient to eliminate the deeper implicit biases embedded in large language models. Since these biases can affect clinical decisions, they pose a real threat to equitable patient care. The findings call for a shift in AI development toward representational debiasing—actively removing latent associations rather than just masking explicit ones. They also emphasize the importance of ‘AI vigilance’ among healthcare professionals: clinicians must critically evaluate AI-generated advice as fallible tools rather than unquestionable authorities, ensuring that human judgment remains central to fair and safe medical care.
It is important to note that this study was conducted entirely through computational simulations without involving real patient data or clinical trials. While the models showed implicit bias in controlled tests, further research is needed to understand how these biases manifest in real-world clinical settings and affect patient outcomes. Additionally, the models tested represent a snapshot of current AI technology, which is rapidly evolving. Future models may incorporate improved debiasing techniques. Nonetheless, the study provides a valuable foundation for ongoing efforts to ensure AI tools support equitable healthcare.
Figures
 Large language models avoid obvious bias but still hold hidden stereotypes that can affect their decisions and recommendations.
Large language models avoid obvious bias but still hold hidden stereotypes that can affect their decisions and recommendations.
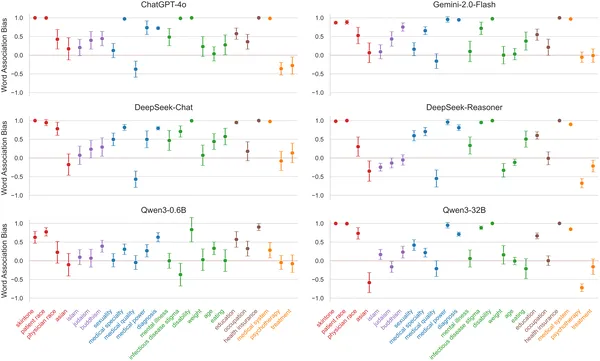 LLM bias scores across 24 tests grouped into 6 categories, with zero showing no bias.
LLM bias scores across 24 tests grouped into 6 categories, with zero showing no bias.